Automatic document scanning for a paperless office
This project aimed to create a fully automated pipeline running on a RaspberryPi to digitalize incoming mail, documents, and receipts at the push of a button. The code can be found at github.
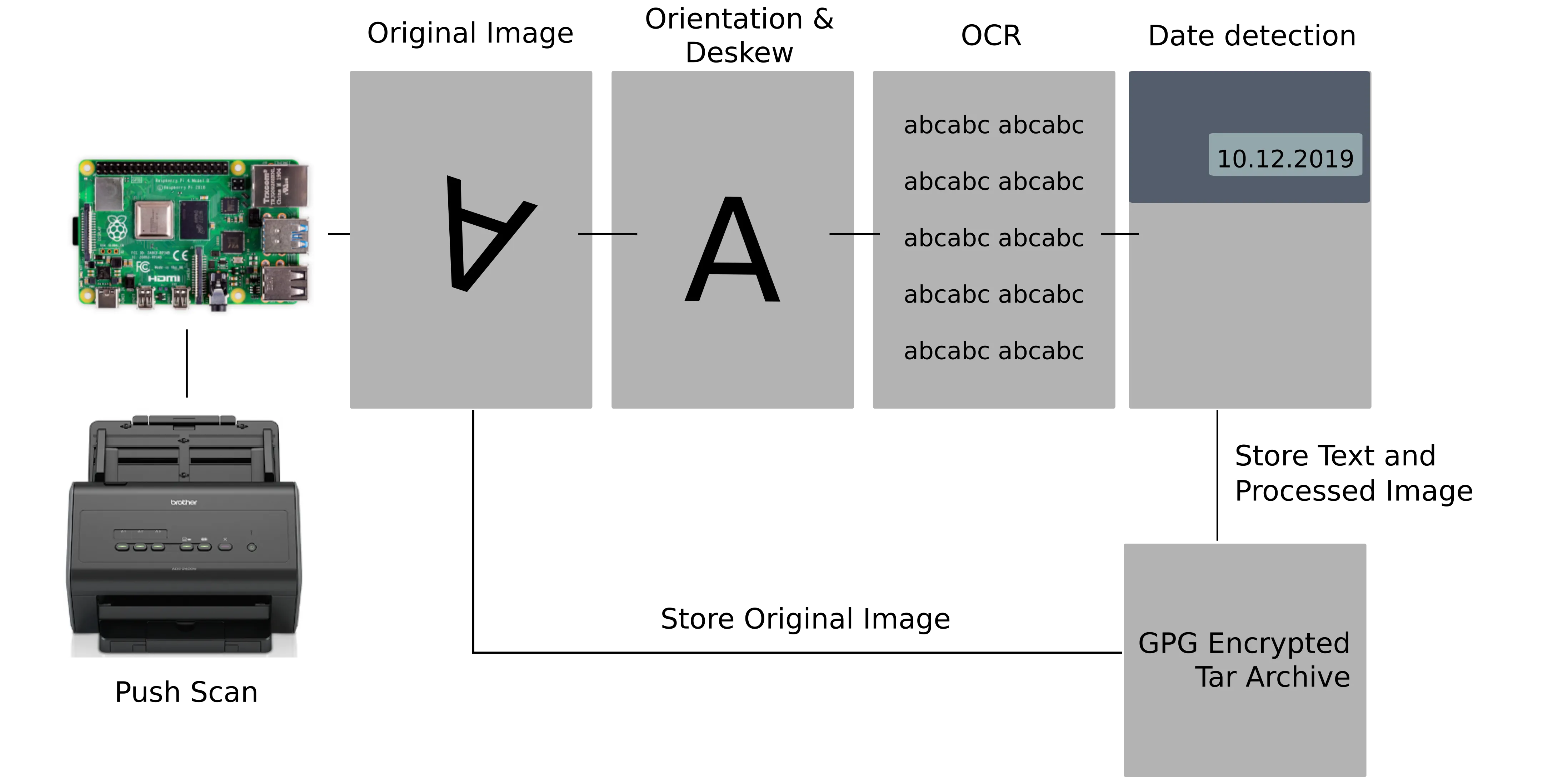
The scanner
It starts with a network-attached scanner that can directly scan to a network destination. I choose the Brother ADS-2400N as it has automatic paper feeding, duplex scanning, and three prominent hardware buttons at the front, each programmed with a preset function. It supports WebDAV (labeling it SharePoint) as a network destination, which is easy to capture in python.
Receiving the documents and processing the images
A python script waits for the individual images of the pages using the WebDAV (HTTP) protocol. As the scanner queries the folder index XML before starting sending a new batch of document pages, it is easy to group pages together into a document. Any error in receiving the document will trigger an HTTP error response, which will result in an error message on the scanner.
The new document is added to a queue, which will be processed in the background. Any error here will retain the original image. Tesseract is used to detect the text orientation; the image is deskewed using opencv and thumbnails are generated. Using tesseract, the image is converted into text extracted into an hocr xml format, which includes the location information. Once the text is available, it tries detecting the document’s date within the letterhead. A well enough working heuristic is looking at all text blocks within the first 35% of the document and using regexes to detect potential date formats then taking the topmost.
The original image, the processed images, the document date, and text are stored in a folder stored in a tar archive. File names are chosen to follow the convention used by openpaper, an document library tool for gnome. As the documents often contain sensitive data, all files are then encrypted using GPG.
Document Viewer
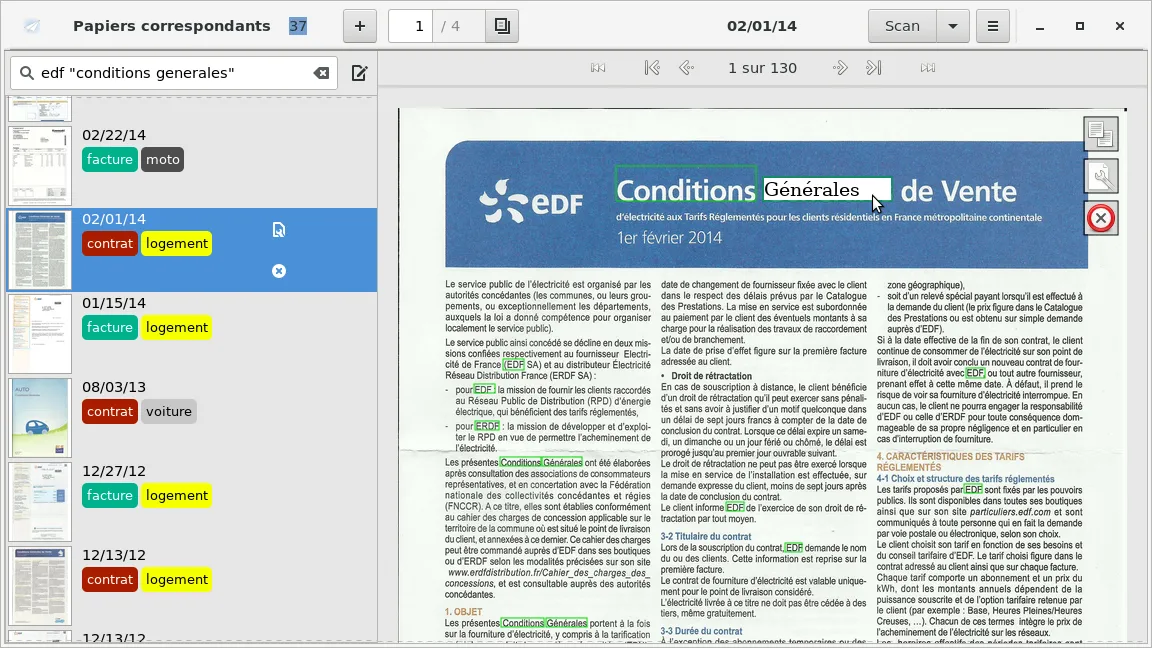
The project is inspired by the paperwork software and generates a compatible file structure. This allows us to use the software as a viewer and local library on a client. New documents can be periodically synced to the client into the paperwork folder.
Deployment
It is packaged as a docker based addon for the homeassistant/hassio ecosystem and can be installed
using the repository https://github.com/gregod/hassio-addon-repo. Any successful scan triggers an event within the homeassistant system.
Syncing the documents
The current version requires that documents must be pulled using rsync to a client. The better option would be to automatically commit new documents to a git annex repository and pushing them to a remote backup location. Immediately deleting the documents from the processing server could spare the need for the gpg encryption.